
So activation functions. What do we know about them, except for the mystery of horrible naming conventions (more on that later 🧐) and why do we need them (assuming you care at all)?
The idea, in fact, is so easy that even your cat can understand it. First of all, we have something similar in our brains. Let’s look at the simplified neuron (organic or artificial):
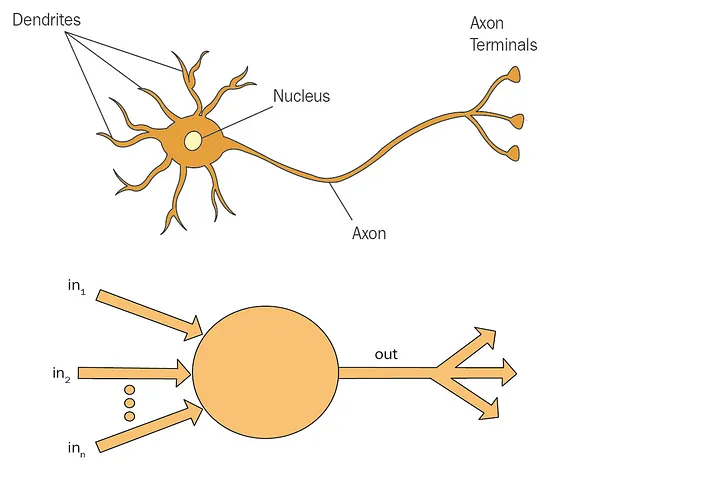
A neuron takes in a bunch of inputs and somehow processes them into something useful as an output. Since neurons are connected — that output is then potentially sent to another neuron as an input.
A neuron just calculates a weighted sum of its inputs (no kidding, that’s all the magic it’s doing). The key here is weighted. So it multiplies all inputs by a certain parameter called weight. As we discussed in the article here — weights are calculated during the training process, that’s the main goal of training.
An artificial neuron therefore has two main properties: weight and bias (don’t worry it’s a good kind of bias, more about this at the end). And all it is doing is a linear transformation on all outputs like this:
y = a * x + b #simple like function hence the name ‘linear’
or
output_1 = weight * input_1 + bias
The complete formula looks like this:
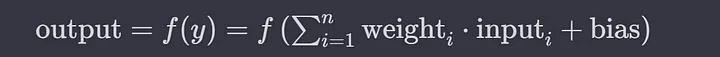
A neuron sums weighted inputs
or
output = sum(weight * inputs + bias)
What it does then looks simple. Because it is simple. But here is a catch: it is too simple! You can stack a lot of those neurons into a network but it wouldn’t help — many complex real-life processes are not linear (🙄 duh)!
To fix this the output is not sent as is, it is transformed first using an activation function. An activation function activates cyborgs that will… oh wait, wrong novel. An activation function is a kind of filter that:
- filters out unimportant information and only leaves important in a certain format
- introduce the necessary non-linearity, allowing the network to learn and model complex patterns
So if you think about it — activation functions make things more complex and that is their primary purpose 🤔… Well, yes, but it follows the old Albert Einstein saying: make it as simple as possible, but no simpler.
So the complete neuron transformation function looks like this:
output = activation_function( sum(weight * inputs + bias) )
What kind of activation function to use depends on one thing — what do we want to achieve. This function can be anything, really, but certain functions work better. Here are the most common ones:
ReLU
Rectifier linear unit.

Sounds suspiciously similar to thermo-rectal cryptanalysis…Not sure I trust this cat anymore
Lots of smart words, prepare to be shocked by really hardcore math here:
if input > 0:
return input
else:
return 0
Wait what? Is that all??? 🤣 Scary name, a simple thing, as always in ML 😭. Take an input and clip it to 0 if it is negative. Who manages the naming division in ML I wonder, my guess is Germans…
ReLU is preferred for these reasons:
- Simplicity and Efficiency: ReLU has a simple mathematical operation which is max(0, x). This simplicity leads to faster computation than more complex functions.
- Solving the Vanishing Gradient Problem: In deep networks, gradients can become very small, preventing the network from learning. Why, well look at another common function sigmoid, for example:
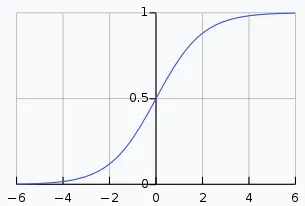
sigmoid graph
See what it does? The bigger the x value, the closer y gets to 1. This means that at very big x values when x changes — y changes are almost unnoticeable. So it almost doesn’t matter what x is after a certain level, y is going to be about 1.
Now let’s look at ReLU:
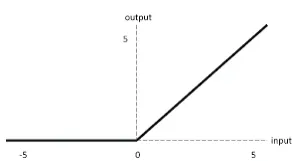
Since ReLU has no cap for all positive inputs, it helps mitigate this problem.
However, ReLU is not without its drawbacks. The most notable one is the “dying ReLU” problem, where many neurons can become inactive and only output zero because, on a big range of values, the output of the function is zero. This can be mitigated with variations of ReLU such as Leaky ReLU or Parametric ReLU (PReLU).
Sigmoid

No, you don’t
Since we’ve started talking about it, let’s tackle another scary-sounding alien monster. The term “sigmoid” originates from the Greek letter “sigma” (Σ, σ), due to the function’s characteristic ‘S’-shaped curve. The word “sigmoid” itself essentially means “S-shaped” in form… Could have just called it S-shaped, you know…🤦♂️
Here is the function graph:
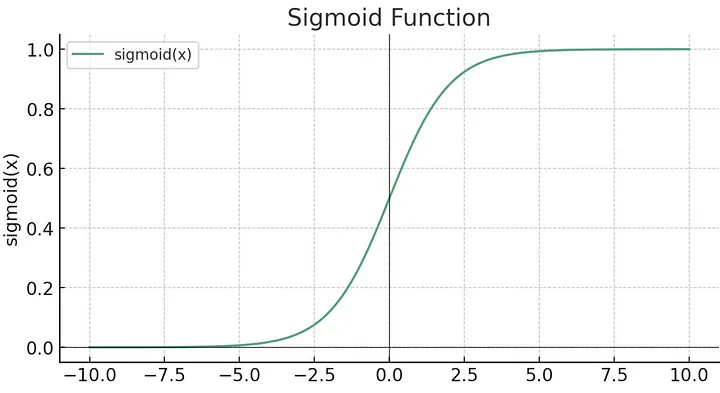
And the formula:
f(x) = 1/(1+e^-x)
Sigmoid is good for binary (yes/no) classification because it takes in any real number as the input and maps it to a number between 0 and 1. It is often used in output layers for this reason (see more on this at the end).
Softmax
As you probably guessed from previous terrible function naming, this one is neither soft nor max. 😂
The softmax function takes as input a vector of K real numbers and normalizes it into a probability distribution consisting of K probabilities proportional to the exponentials of the input numbers. You heard that right buddy 🤣.
Seriously though, what it does — it takes in a list of arbitrary numbers and converts them to a list of proportional probabilities. That is:
Say we have a list [1, 2, 3]
softmax([1, 2, 3]) = [0.09003, 0.24473, 0.66524]
That is it. The sum of the returned probabilities will be 1 (or 100%), as you expect. The bigger the number in an input list (relative to others) — the higher the probability it will have in the output.
One thing to note here is that it takes in a vector (list) of inputs — not a single one. This is different from all previous ones, and the reason is that it works on multiple neurons at once (typically on a whole layer). So it sort of collapses results of a layer into a probabilities distribution output. It is often used in output layers for this reason.
Also, softmax is used in the attention mechanism in transformer architecture, because if you think about it — attention is a sort of ranking a lot of things into a list of the most important ones.
The main thing to understand here is what it means:
- The probability that the input belongs to the first category (corresponding to 1) is approximately 0.09003.
- The probability that the input belongs to the second category (corresponding to 2) is approximately 0.24473.
- The probability that the input belongs to the third category (corresponding to 3) is approximately 0.66524.
This makes the softmax function particularly useful for classification tasks in neural networks where the output needs to represent a probability across multiple classes. For example when we try to understand if a picture is a picture of a dog (1), cat (2), or fish (3).
In fact, if you have just two categories, it reduces to the same formula as sigmoid, so it is kinda like sigmoid only for >2 categories.
It is often used in output layers for the same reasons as sigmoid.
And here is the formula, if you really want to see it:
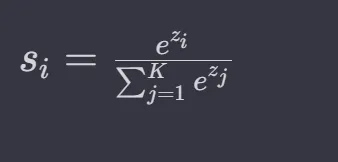
Tanh

Naming is not getting any better, I promise
This one is at least logical. The hyperbolic tangent function is often abbreviated as “tanh” (pronounced “tanch”).
This function takes any real-valued input and outputs values in the range between -1 and 1:
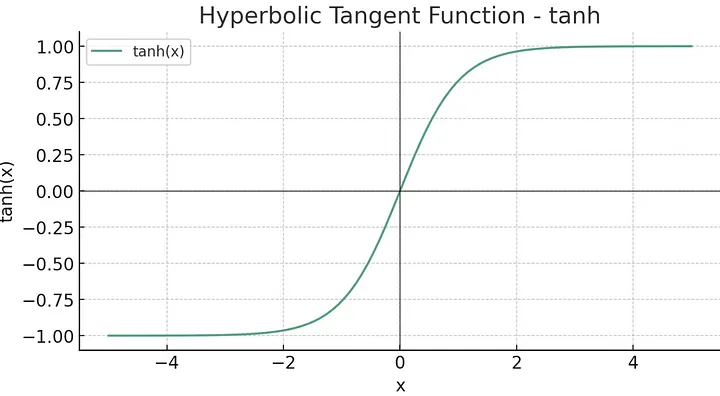
t is very similar to sigmoid and defined as:
tanh(x) = 2 * sigmoid(2x)-1
or
tanh(x) = 2/(1+e^(-2x)) -1
Tanh outputs range from -1 to 1, making it zero-centered. This is advantageous because it can help the learning process since the data flowing through the network will, on average, maintain a mean close to 0, which in turn helps with gradient descent optimization. Sigmoid outputs, on the other hand, are not zero-centered (ranging from 0 to 1), which can lead to what is known as the “vanishing gradients” problem (see ReLU part for explanation). Because of these properties (faster gradient descent, no vanishing gradients), it is often used in hidden layers.
Binary Step Function
The binary step function is one of the simplest types of activation function used in neural networks. It is a threshold-based activation function that is either activated or not, depending on whether the input value x is above or below a certain threshold, which is analogous to an on-off switch. It is commonly used in perceptrons and binary classification problems where the output is expected to be either 0 or 1, like deciding whether an email is spam or not spam.
Historically this was the first used activation function in the context of neural networks. It was used in the earliest type of artificial neuron called the perceptron, developed by Frank Rosenblatt in the late 1950s.
The binary step function can be mathematically defined as:

where θ is the threshold value.
It is not often used in modern neural networks because it isn’t differentiable at the threshold θ, which makes it impossible to use with backpropagation (a method used to train neural networks). Also, it does not provide a probability output, but rather a definite answer, which can be too rigid for complex problems.
There are many more functions, these are just the most commonly used ones.
Neuron layer types and activation functions
Neurons are typically connected in a net similar to this one:
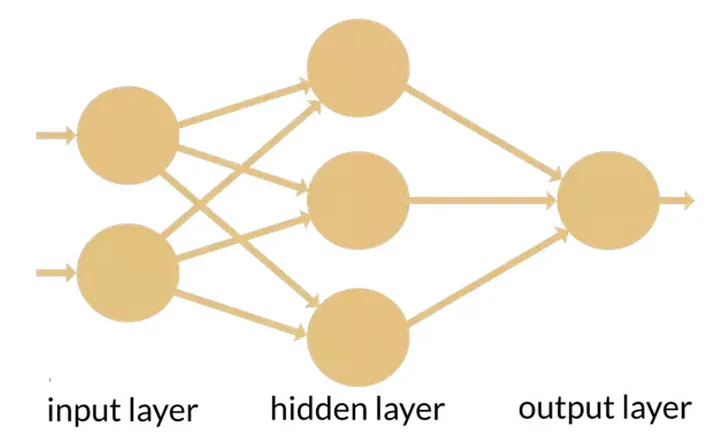
The image was stolen somewhere on the internet…
Important to know here are these three types of layers:
- Input — the first layer of neurons that take the input first.
- Output (frontend) — the last layer, which basically converts everything the neural net thinks into a more or less concrete answer. For example, in the case of softmax used in the output layer — it will give probabilities that a given picture is a cat, a dog, or a fish.
- Hidden (backend) — a bunch of layers that do the actual work.
Different layers use different activation functions because they have different goals (pretty much like different frameworks are used for frontend and backend).
Bias

Yet another victim of the horrible naming department 🙄. Seriously, I would like to know how these people lname their kids.
This is actually an offset. The bias is added to this weighted sum before the activation function is applied.
It allows you to shift the activation function curve up or down. In a way, it “biases” the result that the neuron computes before applying the activation function. Without bias, the neuron’s output is strictly controlled by the weighted sum of its inputs, which might limit the representational capability of the neuron. So the bias provides an additional degree of freedom, allowing the neuron to better fit the data.
That is it, have fun!


