If you’re working with text generation, you’re obviously wondering how to evaluate the quality of your result. This problem may be easier to solve if your output has a good structured form, but what if your text is low-structured? Let’s try to figure it out. Please note that I won’t give an answer to this question at the end of the article, but I will tell you about the beginning of my journey in the problem of text generation evaluation.

Disclaimer
This article doesn’t reveal the technical details of my process and is aimed at discussing the evaluation of text generation rather than the problem of generation itself. This is my initial research, which I would like to extend to a scientific level in the future. I look forward to any constructive discussion in the comments, and maybe you will be the one to adjust my research.
Introduction
Last year at the end of September I published my approach to quantisation and fine-tuning of LLama 2, you can read it in my article. In a nutshell: in the article I generate abstracts of news articles based on headlines from a news dataset. I evaluate the quality of the resulting model generation using cosine score between reference text and generated text with SentenceTransformers library and all-MiniLM-L6-v2 model to take into account the context of the texts. Even at the stage of writing that article, I wondered if this evaluation approach would be the right one?
The focus of this study you’re currently reading is to integrate computed and human assessment to comprehensively evaluate the model’s text generation capabilities, and to justify or reject the use of the cosine similarity metric.
Why Do We Need a Proper Evaluation?
My evaluation case is, of course, artificial. Let’s think about a business case. Suppose we have built a chatbot with a RAG pipeline, where the system is extracting knowledge from a database. The resulting text can also be low-structured and we would probably want the bot to respond in a human-like way. In my opinion, the problem will be how to evaluate that the bot is not hallucinating and the generated text really makes sense.
Hypothesis
- Human evaluation is the ground truth value.
- Can context-aware cosine score be an eligible metric for evaluating text generation?
- What will be the result of the GPT-4 Turbo evaluation? Will it be close to human evaluation?
Evaluation Methodology & Ground Truth
I will use the resulting calculations from my article about Llama 2 quantisation.
The work is done with USA News Dataset from Kaggle and we will evaluate the first 100 lines from the test dataset obtained after train/test split.

This time I replaced the all-MiniLM-L6-v2 model with all-mpnet-base-v2 to achieve a better cosine score calculation. The median in this case will be equal to 0.52. In fact it’s even good that the text generation isn’t perfect, it will allow to see the variation of human evaluations.
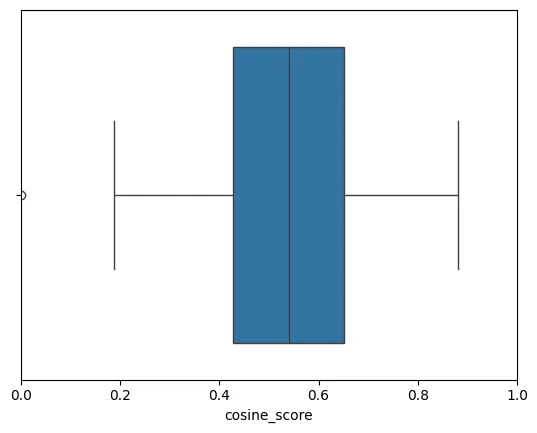
To evaluate the quality of the cosine score, let’s introduce human evaluation as a ground truth. Here is the short description of the human evaluation process:
- Each assessor receives a dataset containing 100 rows.
- They need to assign a quality score by comparing the reference text and the text generated using a model fine-tuned without quantisation.
- The evaluation is done on a five-point scale to make it easier for the assessors to choose a grade. The scale description is the following:
- 0 — Significantly Inferior: The generated text makes no sense and is drastically worse than the reference text, lacking any coherence.
- 1 — Inferior: The generated text has poor coherence, falling substantially short of the reference text’s quality.
- 2 — Fair: The generated text shows some coherence but does not fully match the reference text’s quality. There are noticeable differences.
- 3 — Good: The generated text is coherent and comparable in quality to the reference text, with minor differences.
- 4 — Very Good: The generated text is of high quality, almost on par with the reference text in terms of coherence and relevance, with only minor differences.
- 5 — Excellent: The generated text is on par with the reference text in terms of quality and relevance, demonstrating exceptional coherence.
For the initial study, I was unable to involve a substantial number of people and asked six people to mark up 100 lines of the test dataset. I do realise that it’s not enough, but it will still allow to calculate a basic correlation.
💡 Note: The cosine score ranges between 0 and 1. Since human grades ranges from 0 to 5, let’s normalize the cosine from 0 to 5 as well.
The cosine score normalization process:
# cosine score normalization
min_original = 0
max_original = 1.0
min_new = 0
max_new = 5.0
# linear scaling
results['scaled_cosine_score'] = min_new + (results['cosine_score'] - min_original) / (max_original - min_original) * (max_new - min_new)GPT-4 Turbo Integration
In my research I can’t help but use gpt-4-turbo-preview to evaluate its ability to assess the quality of generated text. The prompt for it is based on the instructions for assessors, hence the model returns an integer from 0 to 5 points. I ran GPT-4 six times per number of human evaluations and averaged the results.
Analysis and Results
Let’s take a look at the scores distribution:
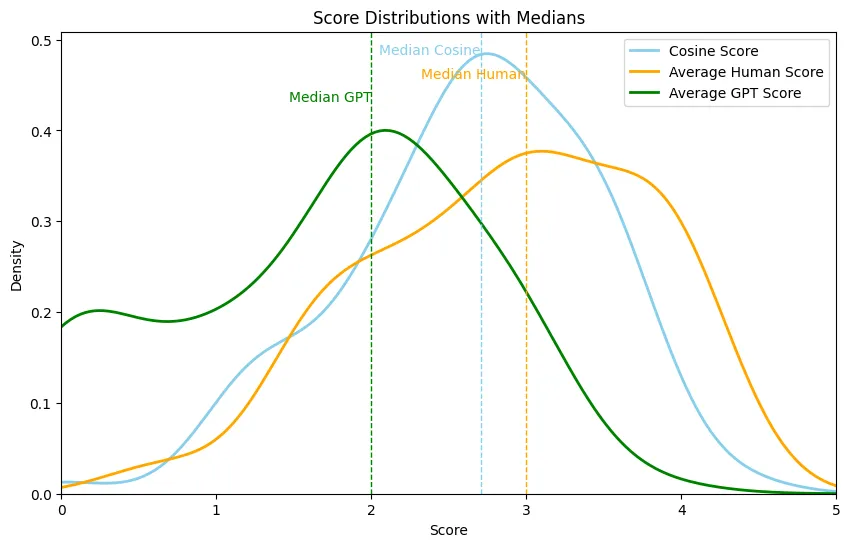
First of all, we can notice that the cosine score tends to the normal distribution in this case. Secondly, we see that median cosine score and median human evaluation are quite close. Can we stop here and end the investigation? Certainly not.
Let’s check the correlation of the scores. The skewness in the distributions suggests that Spearman’s rank correlation might be more appropriate since it doesn’t assume normal distribution and is less sensitive to outliers. The plot below shows Spearman’s rank correlation:
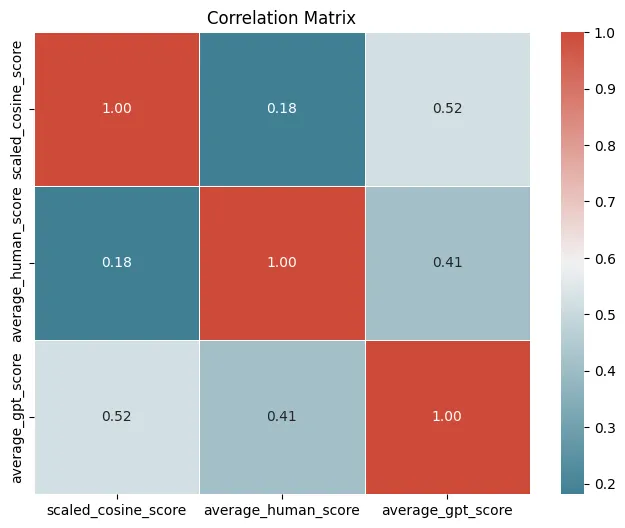
However, the distributions are not highly skewed or have significant outliers, so Pearson’s correlation could still be informative.
Let’s compare both Pearson and Spearman correlation coefficients to get a comprehensive view.
The correlation coefficients for scaled_cosine_score, average_human_score, and average_gpt_score are as follows:
Pearson Correlation:
- Cosine Score & Average Human Score: 0.168 (Low correlation)
- Scaled Cosine Score & Average GPT Score: 0.518 (Moderate positive correlation)
- Average Human Score & Average GPT Score: 0.430 (Moderate positive correlation)
Spearman Correlation:
- Scaled Cosine Score & Average Human Score: 0.181 (Low correlation)
- Scaled Cosine Score & Average GPT Score: 0.521 (Moderate positive correlation)
- Average Human Score & Average GPT Score: 0.412 (Moderate positive correlation)
The results are quite similar for both Pearson and Spearman correlations, indicating robustness in the relationships. The moderate positive correlations between scaled_cosine_score & average_gpt_score, and average_human_score & average_gpt_score suggest some level of association. The correlation between scaled_cosine_score & average_human_score is relatively low, indicating a weaker association.
We can also look at the scatter plots comparing the same evaluation scores:
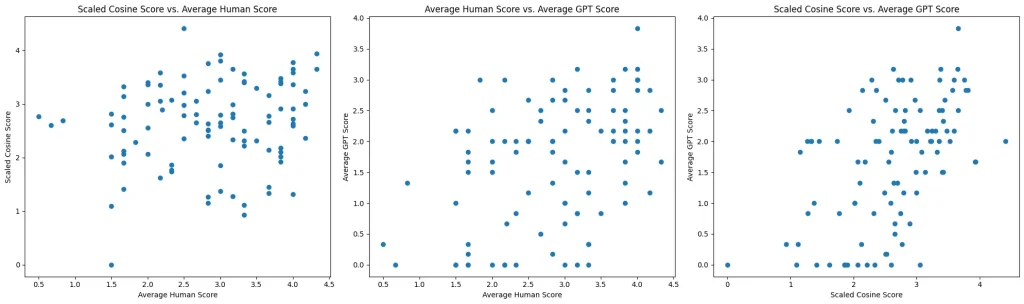
- Cosine vs. Human Score: The lack of a clear trend or pattern suggests that the cosine score might not align consistently with human evaluation across the dataset.
- Human vs. GPT Score: The distribution of points appears somewhat more clustered than in the first plot, but there still isn’t a clear linear relationship. It shows that while GPT might somewhat reflect human scoring, there are instances where the scores differ significantly.
- Cosine vs. GPT Score: The third plot shows the relationship between the
scaled_cosine_scoreand theaverage_gpt_score. This plot also shows a spread without a clear pattern, indicating variability in how the GPT scores relate to the cosine scores.
Overall Interpretation:
The lack of a strong linear pattern in these plots suggests that using any one of these scores as a standalone metric might not provide a complete picture of text generation quality. This underscores the importance of considering multiple metrics for a comprehensive evaluation, which could include a mix of quantitative scores (like cosine similarity) and qualitative insights (from human evaluators or GPT-4).
💡 Cosine score and GPT-4 evaluations provide insights but may not fully capture nuanced human evaluation, especially in low-structured texts.
Conclusion
The analysis and the visualization conducted provide several insights and raise some interesting points about the relationship between scaled_cosine_score, average_human_score, and average_gpt_score in the context of evaluating text generation quality. Let’s sum up here what we found out:
Correlation Between Scores:
scaled_cosine_scorevs.average_human_score: The low correlation indicates that the cosine similarity of embeddings doesn’t align strongly with human assessment. This might be due to several reasons such as the nuanced understanding of text by humans which might not be fully captured by cosine similarity of embeddings.scaled_cosine_scorevs.average_gpt_scoreandaverage_human_scorevs.average_gpt_score: The moderate positive correlation suggests that the GPT-4 evaluation has some level of agreement with both the cosine score and the human score. This could indicate that the GPT-4 captures aspects of the text quality that are recognized by both the cosine similarity method and human evaluators.
Median Values Close but Low Correlation:
- The median values of
scaled_cosine_scoreandaverage_human_scorebeing close suggest that on a central tendency, the scores are similar. However, the low correlation indicates that this similarity doesn’t hold across the dataset. In other words, for some texts, the cosine score might significantly differ from human evaluation, while for others, it might be quite close.
Evaluation of Text Generation:
- Cosine Score with Contextual Embeddings: While cosine similarity offers a possible way to assess text generation, it might not fully capture aspects such as coherence, contextuality, and creativity that human evaluators can perceive. This might be why the correlation with
average_human_scoreis not very strong. - GPT-4 API for Evaluation: The use of GPT-4 API introduces an AI’s perspective in the evaluation process. The moderate correlation with both human and cosine scores suggests that it might be capturing aspects of text quality that are somewhat aligned with both methods. However, the extent to which it agrees or disagrees with human evaluation would need further investigation, possibly through qualitative analysis or more advanced quantitative methods.
Considerations for Low-Structure Text Generation:
- Texts with low structure or creative content might be particularly challenging for automated evaluation methods, including both cosine similarity and AI-based evaluators like GPT-4. The nuances and the creative aspects might be missed or misinterpreted.
- In such cases, combining multiple evaluation methods (like cosine similarity, GPT-4 evaluation, and human grades) and looking for consensus or significant discrepancies can provide a more holistic view of the text quality.
💡 In summary, while the results show some level of agreement between the different evaluation methods, they also highlight the complexity and challenges in automating the evaluation of low-structure text generation.
Next Steps

Let’s list what can be done next:
- Qualitative Analysis: It might be helpful to conduct a qualitative analysis of cases where there’s a significant discrepancy between the scores to understand what each method might be capturing or missing.
- Advanced GPT-4 Fine-tuning: The Fine-tuning of GPT-4 might provide insights or improve alignment with the human evaluation.
- Experimentation with Different Embeddings or Models: Experimenting with different types of embeddings or other language models might yield different or improved results.
- Methodology Refinement: To move the research further, it is necessary, at least, to expand the evaluation methodology, to clarify the guidelines for human evaluation, to address the subjectivity of human evaluation, including.
A multi-method approach, combining automated scores with human judgment, and further refinement of the evaluation methods might be necessary to capture the multifaceted nature of text quality.


