It is surprisingly easy to build an image recognition system nowadays.. Even 2 years ago you would have to be a CV (Computer Vision) expert to do that, now pretty much anyone can build and (even more surprisingly) deploy and use a model for free. So we are going to do just that.
Btw, the approach we are going to use is based on DriveTrain, but you don’t need to know it really to understand the code.
You, of course, always wondered if you have ever taken a picture of a UFO, so wonder no longer! We are going to build a UFO detector, no less.
We are going to be using Google Collab notebooks but you can use any Jupyter compatible notebooks with fast.ai. The whole notebook for this article is here.
Gathering Data
So in order to train a model we need data, and preferably quality data. Where do we get it? Well, the same place we all get data from — Google search. In this case, we are going to use DuckDuckGo as it is completely free and requires no setup.
We are going to search for pictures of UFOs and random jet pictures (as UFOs are typically flying) and train on that.
First, let’s write search_images_ddg function:
import requests
import regex as re
import json
def search_images_ddg(key,max_n=200):
"""Search with DuckDuckGo and return a unique urls of 'max_n' images
(Adopted from https://github.com/deepanprabhu/duckduckgo-images-api)
"""
url = 'https://duckduckgo.com/'
params = {'q':key}
res = requests.post(url,data=params)
searchObj = re.search(r'vqd=([\d-]+)\&',res.text)
if not searchObj: print('Token Parsing Failed !'); return
requestUrl = url + 'i.js'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0'}
params = (('l','us-en'),('o','json'),('q',key),('vqd',searchObj.group(1)),('f',',,,'),('p','1'),('v7exp','a'))
urls = []
while True:
try:
res = requests.get(requestUrl,headers=headers,params=params)
data = json.loads(res.text)
for obj in data['results']:
urls.append(obj['image'])
max_n = max_n - 1
if max_n < 1: return L(set(urls)) # dedupe
if 'next' not in data: return L(set(urls))
requestUrl = url + data['next']
except:
passPlease note that this function is going to fail to fetch results sometimes (quite often), so you may have to run it multiple times.
Now let’s setup fastbook API:
! [ -e /content ] && pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.widgets import *With that let’s download and clean the data:
ufos_urls = search_images_ddg('UFO')
print(len(ufos_urls))
planes_urls = search_images_ddg('Airplane')
print(len(planes_urls))In case of success you should see how many images were found:
>> 200
Let’s see what we got:
from fastdownload import download_url
dest = 'images/UFO.jpg'
download_url(ufos_urls[0], dest)
im = Image.open(dest)
display(im.to_thumb(256,256))
dest = 'images/plane.jpg'
download_url(planes_urls[0], dest)
im = Image.open(dest)
display(im.to_thumb(256,256))
>>

Nice, now let’s download more images into a separate folder:
root = Path("xfiles")
if not root.exists():
root.mkdir()
def download(directory_name, urls):
path = Path(root/directory_name)
if not path.exists():
path.mkdir()
dest = path
download_images(dest, urls=urls)
fns = get_image_files(path)
print(fns)
download('UFOs', ufos_urls)
download('Planes', planes_urls)
DataLoaders
Often when we download files from the internet, there are a few that are corrupt. Let’s check and delete those:
def verify(directory_name):
fns = get_image_files(Path(root/directory_name))
failed = verify_images(fns)
print(f"Failed {directory_name} {len(failed)}")
print(failed)
failed.map(Path.unlink)
failed.map(fns.remove)
verify('UFOs')
verify('Planes')Now that we have downloaded data, we need to assemble it in a format suitable for model training. In fastai, that means creating an object called DataLoaders. DataLoaders is a class that just stores whatever DataLoader objects you pass to it, and makes them available as train and valid (that is — the training and validation sets).
To turn our downloaded data into a DataLoaders object we need to tell fastai at least four things:
- What kinds of data we are working with
- How to get the list of items
- How to label these items
- How to create the validation set
ufos = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))
dls = ufos.dataloaders(root)Let’s look at each parameter one by one: First, we provide a tuple where we specify what types we want for independent and dependent variables. The independent variable is the thing we are using to make predictions, and the dependent variable is what we are trying to predict. Here we are trying to use image data to predict a category (plane or UFO):
blocks=(ImageBlock, CategoryBlock)For this DataLoaders our underlying items will be file paths. We have to tell fastai how to get a list of those files. The get_image_files function takes a path, and returns a list of all of the images in that path (recursively, by default):
get_items=get_image_filesThere are many ways to define a validation set. You can provide a CSV file with the names of files that are used for validation, etc. In our case we are going to simply randomly choose 20% of these files as a validation set:
splitter=RandomSplitter(valid_pct=0.2, seed=7)The independent variable is often referred to as x and the dependent variable is often referred to as y. Here, we are telling fastai what function to call to create the labels in our dataset:
get_y=parent_labelparent_label is a function built into fastai that simply gets the name of the folder a file is in (in our case called ‘UFOs’ and ‘Jets’ for jets).
Our images are all different sizes, and this is a problem for deep learning: we don’t feed the model one image at a time but several of them. To group them in a big array (usually called a tensor) that is going to go through our model, they all need to be of the same size. So, we need to add a transform that will resize these images to the same size. Item transforms are transforms that run on each individual item, whether it be an image, category, or so forth. fastai includes many predefined transforms; we use the Resize transform here:
item_tfms=Resize(128)Now let’s see what we’ve got:
dls.valid.show_batch(max_n=4, nrows=1)>>

Note that searching for planes sometimes returns weird stuff too :). That is going to affect training somewhat. Ideally, we need to clean the data, but let’s do training without that and see what happens.
We now create our Learner and fine-tune it in the usual way:
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)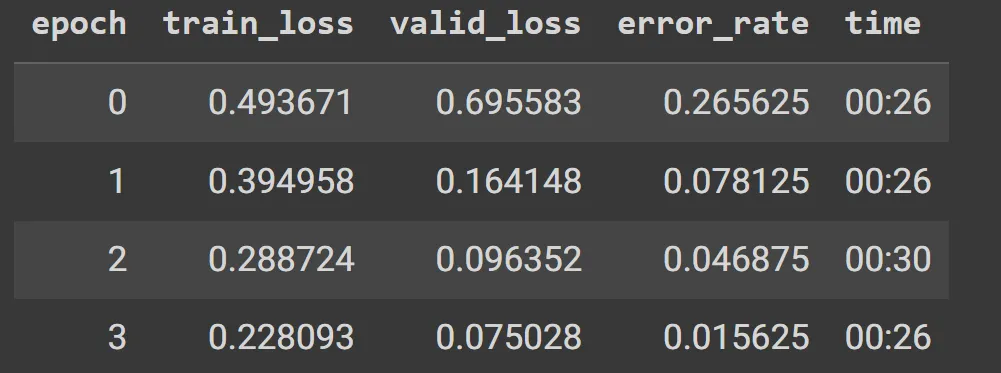
The loss is a number that is higher if the model is incorrect (especially if it’s also confident of its incorrect answer), or if it’s correct, but not confident of its correct answer.
train_loss reflects how well the model fits the training data based on training data, while valid_loss is calculated using the validation dataset and reflects how well the model generalizes to new, unseen data.
As you can see results are ok, but not great. I think it is mainly because of the quality of data and the fact that some UFOs actually look like planes from a distance (and I think in many cases they are 🙂 ) so even many people can distinguish them. Btw, have you listened to Lex Fridman’s podcast on UFOs?
Now let’s see what mistakes the model is making. To visualize this, we can create a confusion matrix:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
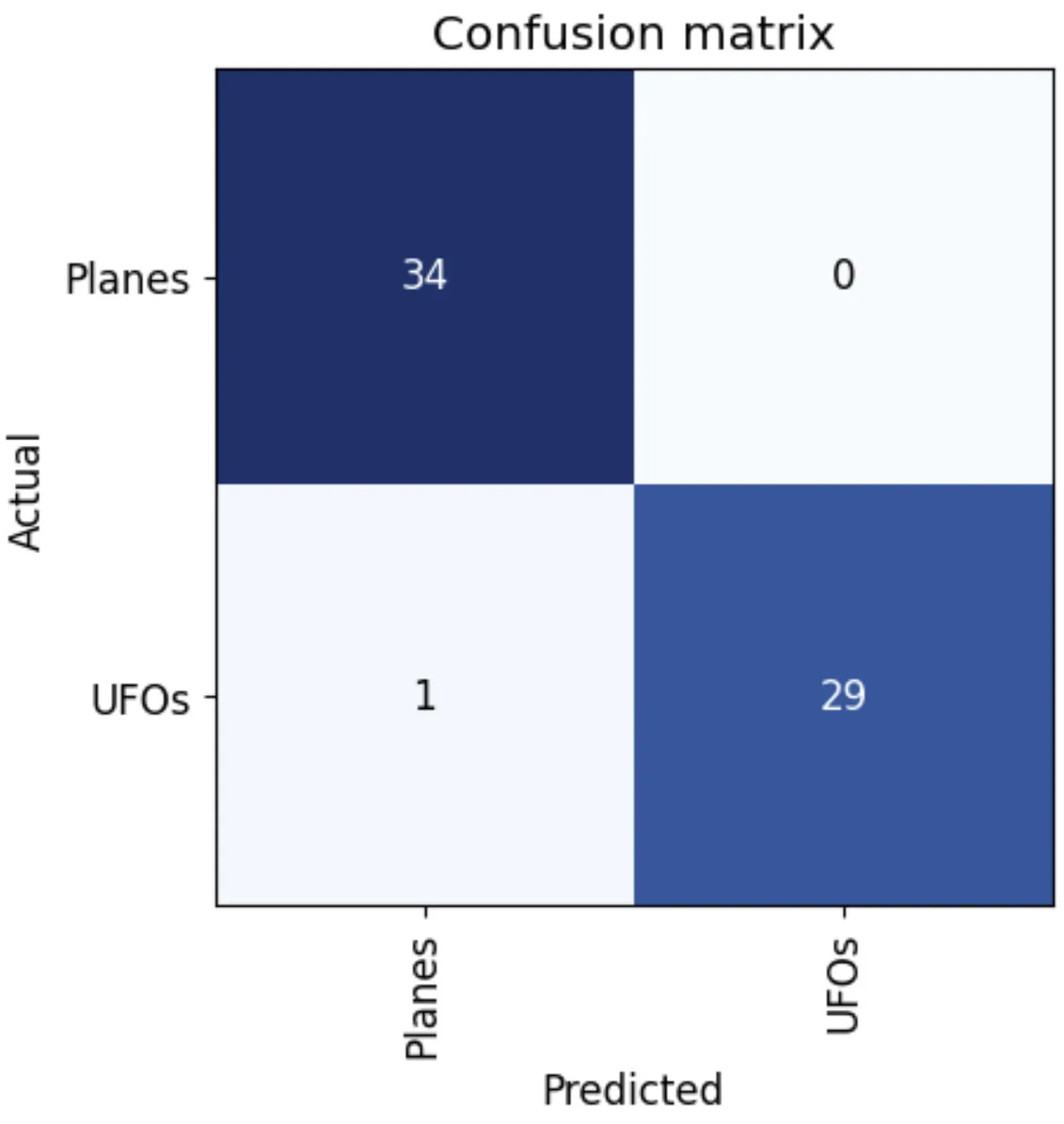
Interestingly, not that bad.
plot_top_losses shows us the images with the highest loss in our dataset. Let’s see:
interp.plot_top_losses(5, nrows=1)
As expected pretty vague images, maybe except for the first one, which is obviously a UFO.
Now let’s create a simple UI to test the model. IPython widgets are GUI components that bring together JavaScript and Python functionality in a web browser and can be created and used within a notebook.
out_pl = widgets.Output()
out_pl.clear_output()
btn_upload = widgets.FileUpload()
def on_upload_change(change):
if len(btn_upload.data) > 0 :
img = PILImage.create(btn_upload.data[-1])
with out_pl: display(img.to_thumb(128,128))
btn_upload.observe(on_upload_change, names='_counter')
def on_click_classify(change):
img = PILImage.create(btn_upload.data[-1])
print(learn.predict(img))
btn_run = widgets.Button(description='predict')
btn_run.on_click(on_click_classify)
VBox([widgets.Label('Test your image!'),
btn_upload, btn_run, out_pl])And test:
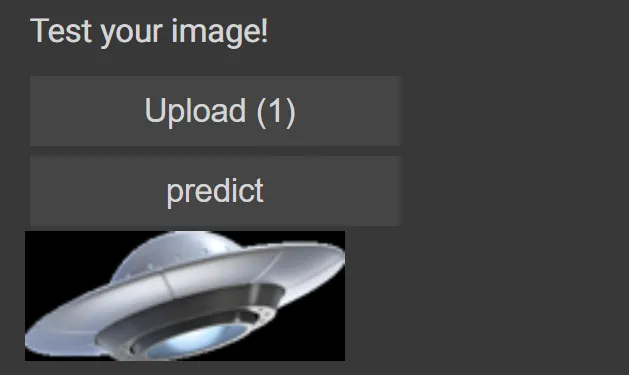
This should return: (‘UFOs’, tensor(1), tensor([0.0016, 0.9984])) or something like that. In this case, the model is quite sure this is a UFO, which is correct! Congratulations on your first UFO detector!


