If you haven’t heard about RAG from your refrigerator yet, you surely will very soon, so popular this technique has become. Surprisingly, there is a lack of complete guides that consider all the nuances (like relevance assessment, combating hallucinations, etc.), instead of just fragmented pieces. Based on our experience, I have compiled a guide that covers this topic thoroughly.

So, why do we need RAG?
You could use LLM models like ChatGPT to create horoscopes (which it does quite successfully), or for something more practical (like work). However, there is a problem: companies typically have a multitude of documents, rules, regulations, etc., about which ChatGPT knows nothing, of course.
What can be done?
There are two options: retrain the model with your data or use RAG.
Retraining is long, expensive, and most likely will not succeed (don’t worry, it’s not because you’re a bad parent; it’s just that few people can and know how to do it).
The second option is Retrieval-Augmented Generation (also known as RAG). Essentially, the idea is simple: take a good existing model (like OpenAI’s), and attach a company information search to it. The model still knows little about your company, but now it has somewhere to look. While not as effective as if it knew everything, it’s sufficient for most tasks.
Here is a basic overview of the RAG structure:
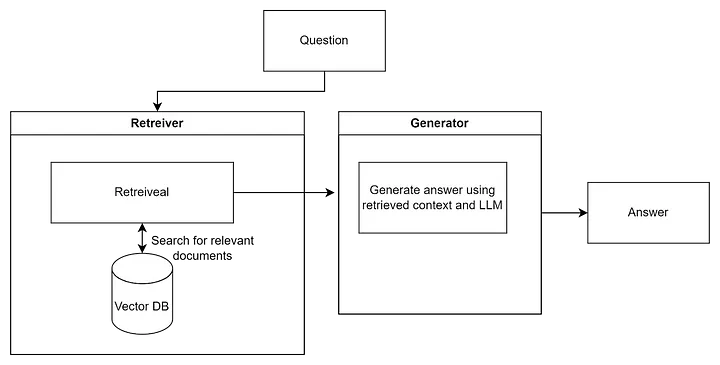
The Retriever is part of the system that searches for information relevant to your query (similarly to how you would search in your own wiki, company documents, or on Google). Typically, a vector database like Qdrant, where all the company’s indexed documents are stored, is used for this purpose, but essentially anything can be used.
The Generator receives the data found by the Retriever and uses it (combines, condenses, and extracts only the important information) to provide an answer to the user. This part is usually done using an LLM like OpenAI. It simply takes all (or part) of the found information and asks to make sense of it and provide an answer.
Here is an example of the simplest implementation of RAG in Python and LangChain.
import os
import wget
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
from langchain import OpenAI
from langchain_community.document_loaders import BSHTMLLoader
from langchain.chains import RetrievalQA
#download War and Peace by Tolstoy
wget.download("http://az.lib.ru/t/tolstoj_lew_nikolaewich/text_0073.shtml")
#load text from html
loader = BSHTMLLoader("text_0073.shtml", open_encoding='ISO-8859-1')
war_and_peace = loader.load()
#init Vector DB
embeddings = OpenAIEmbeddings()
doc_store = Qdrant.from_documents(
war_and_peace,
embeddings,
location=":memory:",
collection_name="docs",
)
llm = OpenAI()
# ask questions
while True:
question = input('Your question: ')
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=doc_store.as_retriever(),
return_source_documents=False,
)
result = qa(question)
print(f"Answer: {result}")
It sounds simple, but there’s a nuance:
Since the knowledge isn’t hardcoded into the model, the quality of the answers depends heavily on what the Retriever finds and in what form. It’s not a trivial task, as in the typical chaos of company documents, even people usually have a hard time understanding them. Documents and knowledge are generally stored in poorly structured forms, in different places, sometimes as images, charts, handwritten notes, etc. Often, information in one place contradicts information in another, and one has to make sense of all this mess.
Part of the information simply makes no sense without context, such as abbreviations, acronyms adopted by the company, and names and surnames.
What to do?
This is where various search optimizations (aka hacks) come into play. They are applied at different stages of the search. Broadly, the search can be divided into:
- Initial processing and cleaning of the user’s question
- Data searching in repositories
- Ranking of the results obtained from the repositories
- Processing and combining results into an answer
- Evaluating the response
- Applying formatting, stylistic, and tone
Let’s take a detailed look at each stage:
Initial processing of the user’s question
You wouldn’t believe what users write as questions. You can’t count on them being reasonable — the question could be phrased as a demand, statement, complaint, threat, just a single letter, or AN ENTIRE essay the size of “War and Peace.” For example:

What “and”?
or

The input needs to be processed, turning it into a query that can be used to search for information. To solve this problem, we need a translator from the user language to the human language. Who could do this? Of course, an LLM. Basically, it might look like this:

The simplest option — ask the LLM to reformulate the user’s request. But, depending on your audience, this might not be enough!!!!!1111
Then a slightly more complex technique comes into play — RAG Fusion.
RAG Fusion
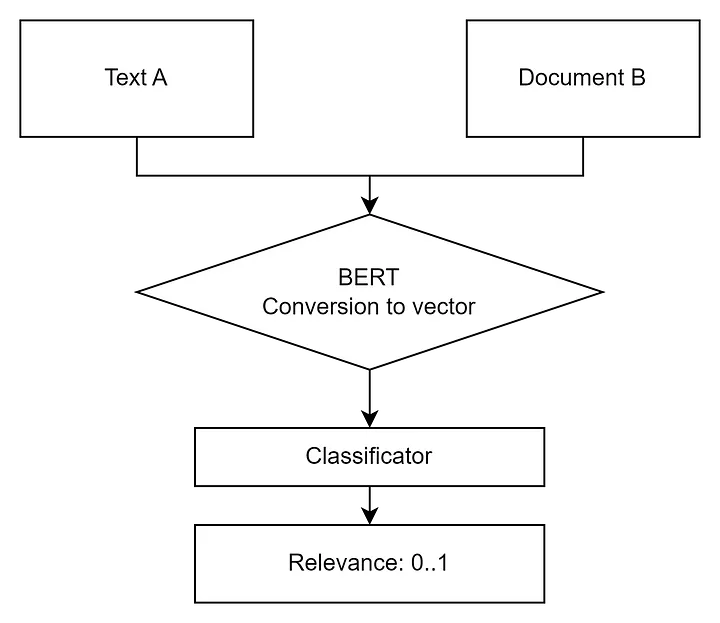
The idea is to ask the LLM to provide several versions of the user’s question, conduct a search based on them, and then combine the results, having ranked them beforehand using some clever algorithm, such as a Cross-Encoder. Cross Encoder works quite slowly, but it provides more relevant results, so it’s not practical to use it for information retrieval — however, for ranking a list of found results, it’s quite suitable.
Remarks about Cross and Bi Encoders
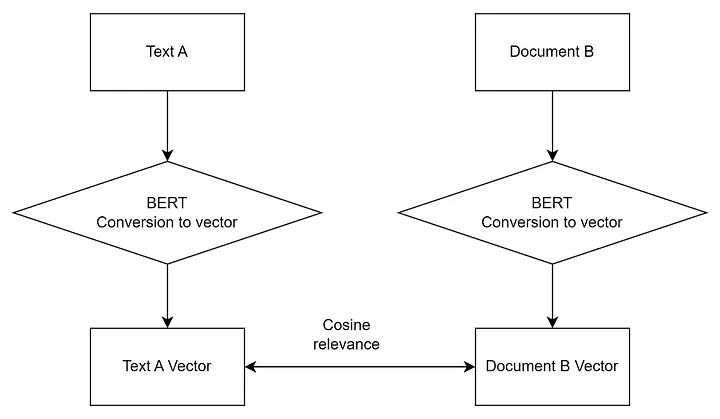
Vector databases use Bi-encoder models to compute the similarity of two concepts in vector space. These models are trained to represent data in vector form and, accordingly, during a search, the user’s query is also turned into a vector, and vectors closest to the query are returned. However, this proximity does not guarantee that it is the best answer.
Cross-Encoder works differently. It takes two objects (texts, images, etc.) and returns their relevance (similarity) relative to each other. Its accuracy is usually better than that of a Bi-Encoder. Typically, more results than necessary are returned from the vector database (just in case, say 30) and then they are ranked using a Cross-Encoder or similar techniques, with the top 3 being returned.
User request preprocessing also includes its classification. For example, requests can be subdivided into questions, complaints, requests, etc. Requests can further be classified as urgent, non-urgent, spam, or fraud. They can be classified by departments (e.g., accounting, production, HR), etc. All this helps narrow down the search for information and, consequently, increases the speed and quality of the response.
For classification, an LLM model or a specially trained neural network classifier can be used again.
Data Search in Repositories
The so-called retriever (the first letter in RAG) is responsible for the search.
Usually, a vector database serves as the repository where company data from various sources (document storage, databases, wikis, CRM, etc.) are indexed. However, it’s not mandatory and anything can be used, such as Elasticsearch or even Google search.
I will not discuss non-vector base searches here, as the principle is the same everywhere.
Digression about Vector Databases
A vector database (or vector storage. I use these terms interchangeably, although technically they are not the same) is a type of data storage optimized for storing and processing vectors (which are essentially arrays of numbers). These vectors are used to represent complex objects, such as images, texts, or sounds, as vectors in vector spaces for machine learning and data analysis tasks. In a vector database (or, more precisely, in vector space), concepts that are semantically similar are located close to each other, regardless of their representation. For example, the words “dog” and “bulldog” will be close, whereas the words “lock” (as in a door lock) and “lock” (as in a castle) will be far apart. Therefore, vector databases are well suited for semantic data search.
Most Popular Vector Databases (as of now):
- QDrant — open-source database
- Pinecone — cloud-native (i.e., they will charge you a lot) database
- Chroma — another open-source database (Apache-2.0 license)
- Weaviate — open under BSD-3-Clause license
- Milvus — open under Apache-2.0 license
- FAISS — a separate beast, not a database but a framework from Meta
Also, some popular non-vector databases have started offering vector capabilities:
- Pgvector for PostgreSQL
- Atlas for Mongo
To improve results, several main techniques are used:
Ensemble of retrievers and/or data sources — a simple but effective idea, which involves asking several experts the same question and then somehow aggregating their answers (even just averaging) — the result on average turns out better. In some sense, this is analogous to “Ask the Crowd.”
As an example — the use of multiple types of retrievers from Langchain. Ensembling is particularly useful when combining sparse retrievers (like BM25) and dense retrievers (working based on embedding similarities, such as the same vector databases) because they complement each other well.
Dense Retriever — typically uses transformers, such as BERT, to encode both queries and documents into vectors in a multidimensional space. The similarity between a query and a document is measured by the proximity of their vectors in this space, often using cosine similarity to assess their closeness. This is the basis on which vector databases are built. Such a model better understands the semantic (meaningful) value of queries and documents, leading to more accurate and relevant results, especially for complex queries. Because the model operates at the level of meaning (semantics), it handles paraphrasing and semantic similarities well.
Sparse Retriever — uses traditional information retrieval methods, such as TF-IDF (Term Frequency) or BM25. These methods create sparse vectors, where each dimension corresponds to a specific term from a predefined dictionary. The relevance of a document to a user’s query is calculated based on the presence and frequency of the terms (or words, let’s say) of the query in the document. It is effective for keyword-based queries and when the terms of the query are expected to be directly present in the relevant documents. They don’t always work as accurately as dense retrievers, but are faster and require fewer resources for searching and training.
The EnsembleRetriever then ranks and combines results using, for example, Reciprocal Rank Fusion:
Example of an ensemble:
!pip install rank_bm25
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import Chroma
embedding = OpenAIEmbeddings()
documents = "/all_tolstoy_novels.txt"
bm25_retriever = BM25Retriever.from_texts(doc_list)
bm25_retriever.k = 2
vectorstore = Chroma.from_texts(doc_list, embedding)
vectorstore_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, vectorstore_retriever ], weights=[0.4, 0.6])
docs = ensemble_retriever.get_relevant_documents("War and Peace")
How to choose the right strategy from all this zoo? Experiment. Or use a framework, for example, https://github.com/Marker-Inc-Korea/AutoRAG.
By the way, it’s also possible to ensemble several LLMs, which also improves the result. See “More agents is all you need.”
RELP
This is another method for data retrieval, Retrieval Augmented Language Model based Prediction. The distinction here is in the search step — after we find information in the vector storage, including using the techniques mentioned above, we use it not to generate an answer using an LLM but to generate example answers (via few-shot prompting) for the LLM. Based on these examples, the LLM effectively learns and responds based on this mini-training to the posed question. This technique is a form of dynamic learning, which is much less costly than re-training the model using standard methods.
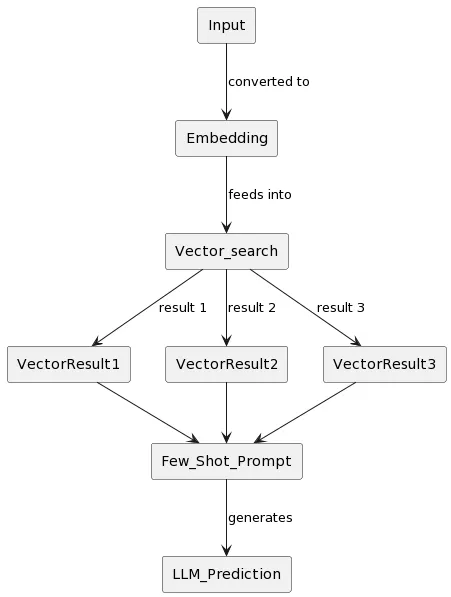
Remarks about few-shot (learning) prompting
There are two similar LLM prompting techniques: zero-shot and few-shot. Zero-shot is when you ask your LLM a question without providing any examples. For instance:

Few-shot is when you first give the LLM several examples on which it trains. This significantly increases the likelihood of getting a relevant answer in the relevant form. For example:

As you can see, not everything is always obvious, and examples help to understand.
Ranking, Combining, and Evaluating the Obtained Results
We have already partially touched on this topic as part of RAG Fusion and the ensembling of retrievers. When we extract results from a (vector) storage, before sending this data to an LLM for answer generation, we need to rank the results, and possibly discard the irrelevant ones. The order in which you present the search results to the LLM for answer formulation matters. What the LLM sees first will have a stronger influence on the final outcome (more details here).
Different approaches are used for ranking. The most common include:
- Using a Cross-Encoder (described above) for re-ranking the obtained results and discarding the least relevant (for example, pulling the top 30 results from a vector database (top k), ranking them with a Cross-Encoder, and taking the first 10).
There are already ready-made solutions for these purposes, for example from Cohere.
2. Reciprocal Rank Fusion. The main idea of RRF is to give greater importance to elements occupying higher positions in each set of search results. In RRF, the score of each element is calculated based on its position in the individual search results. This is usually done using the formula 1/(k + rank), where “rank” is the position of the element in a particular set of search results, and “k” is a constant (often set around 60). This formula provides a higher score for elements with a higher rank.
Scores for each element in different sets of results are then summed to obtain a final score. Elements are sorted by these final scores to form a combined list of results.
RRF is particularly useful because it does not depend on the absolute scores assigned by individual search systems, which can vary significantly in their scale and distribution. RRF effectively combines results from different systems in a way that highlights the most consistently highly ranked elements.
3. LLM-based ranking and evaluation: you can relax and simply ask an LLM to rank and evaluate the result 🙂. The latest versions of OpenAI handle this quite well. However, using them for this purpose is costly.
Evaluation of search results in the Vector Store:
Suppose you have made reranking or other changes — how do you determine whether it was beneficial? Did the relevance increase or not? And in general, how well does the system work? This is a quality metric for the information found. It is used to understand how relevant the information your system finds is and to make decisions about further refinement.
You can assess how relevant the results are to the query using the following metrics: P@K, MAP@K, NDCG@K (and similar). These usually return a number from 0 to 1, where 1 is the highest accuracy. They are similar in meaning, with differences in details:
P@K means precision at K, i.e., accuracy for K elements. Suppose for a query about rabbits, the system found 4 documents:
[“Wild Rabbits”, “Task Rabbit: modern jobs platform”, “Treatise on Carrots”, “My Bunny: Memoirs by Walter Issac”]
Since Walter Issac’s biography or jobs platforms have nothing to do with rabbits, these positions would be rated 0, and the overall accuracy would be calculated like this:
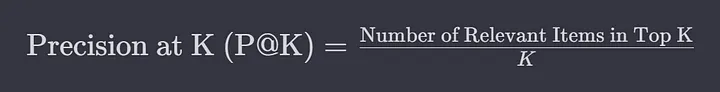
P@K at K=4, or P@4 = 2 relevant / (2 relevant + 2 irrelevant) = ½ = 0.5.
However, this does not take into account the order. What if the returned list looks like this:
[“Task Rabbit: modern jobs platform”, “My Bunny: Memoirs by Walter Issac”, “Wild Rabbits”, “Treatise on Carrots”]
P@K is still 0.5, but as we know, the order of relevant and irrelevant results matters! (both for people and for the LLM that will use them).
Therefore, we use AP@K or average precision at K. The idea is simple: we need to modify the formula so that the order is taken into account and relevant results at the end of the list do not increase the overall score less than those at the beginning of the list:

Or for our example above:
AP@4 = (0 * 0 + 0 *½ + 1 * ⅓ + 1 + 1 * 2/4) .2 = (⅓ + 2/4) / 2 = 0.41
Here are a few questions that arise: how did we assess the relevance of individual elements to calculate these metrics? This is a detective question, a very good one indeed.
In the context of RAG, we often ask an LLM or another model to make an assessment. That is, we query the LLM about each element — this document we found in the vector storage — is it relevant to this query at all?
Now, the second question: is it sufficient to ask just this way? The answer is no. We need more specific questions for the LLM that ask it to assess relevance according to certain parameters. For example, for the sample above, the questions might be:
Does this document relate to the animal type “rabbit”?
Is the rabbit in this document real or metaphorical?
Etc. There can be many questions (from two to hundreds), and they depend on how you assess relevance. This needs to be aggregated, and that’s where:
MAP@K (Mean Average Precision at K) comes in — it’s the average of the sum of AP@K for all questions.
NDCG@K stands for normalized discounted cumulative gain at K, and I won’t even translate that 🙂. Look it up online yourself.
Evaluating the results of the LLM response
Not everyone knows this, but you can ask an LLM (including Llama and OpenAI) not just to return tokens (text) but logits. That is, you can actually ask it to return a distribution of tokens with their probabilities, and see — how confident is the model really in what it has concocted (calculating token-level uncertainty)? If the probabilities in the distribution are low (what is considered low depends on the task), then most likely, the model has started to fabricate (hallucinate) and is not at all confident in its response. This can be used to evaluate the response and to return an honest “I don’t know” to the user.
Using formatting, style, and tone
The easiest item 🙂. Just ask the LLM to format the answer in a certain way and use a specific tone. It’s better to give the model an example, as it then follows instructions better. For instance, you could set the tone like this:
Formatting and stylistics can be programmatically set in the last step of RAG — requesting the LLM to generate the final answer, for example:
question = input('Your question: ')
style = 'Users have become very very impudent lately. Answer as a gangster from a ghetto'
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=doc_store.as_retriever()
)
result = qa(style + " user question: " + question)
print(f"Answer: {result}")
Fine-tuning models
Sometimes you might indeed need further training. Yes, initially I said that most likely you won’t succeed, but there are cases when it is justified. If your company uses acronyms, names/surnames, and terms that the model does not and cannot know about, RAG may perform poorly. For example, it might struggle with searching data by Russian surnames, especially their declensions. Here, a light fine-tuning of the model using LORA can help, to train the model to understand such specific cases. You can use frameworks like https://github.com/bclavie/RAGatouille.
Such fine-tuning is beyond the scope of this article, but if there is interest, I will describe it separately.
Systems based on RAG
There are several more advanced options based on RAG. In fact, new variants are emerging almost every day, and their creators claim that they have become increasingly better…
Nevertheless, one variation stands out — FLARE (Forward Looking Active REtrieval Augmented Generation).
It’s a very interesting idea based on the principle that RAG should not be used haphazardly but only when the LLM itself wants to. If the LLM confidently answers without RAG, then please proceed. However, if it starts to doubt, that’s when more contextual data needs to be searched for. This should not be done just once but as many times as necessary. When, during the response process, the LLM feels it needs more data, it performs a RAG search.
In some ways, this is similar to how people operate. We often do not know what we do not know and realize it only during the search process itself.
I will not go into details here; that is a topic for another article.
This was part one. Part two about advanced RAG is here.
Summary
In this article, I’ve provided a comprehensive guide to Retrieval-Augmented Generation (RAG).
Here’s a quick recap of our journey:
Need and Advantages: I started by discussing why RAG is needed and its benefits over retraining models with custom data.
RAG Structure: Then, I explained the basic structure of RAG, highlighting the roles of the Retriever and Generator components.
Implementation: I walked through an example implementation using Python and LangСhain.
User Query Processing: I delved into processing user queries, including RAG Fusion and Cross-Encoders.
Data Search Techniques: Next, I explored various data search techniques, such as vector databases and ensembling retrievers.
Ranking and Evaluating: I covered the importance of ranking, combining, and evaluating retrieved results to improve response quality.
Advanced Methods: Finally, I discussed optimizations and advanced methods like RELP and FLARE, as well as considerations for fine-tuning models and maintaining response formatting, style, and tone.


